728x90
코뮤니티 모각코 파이썬 크롤링 출석 인증 7일차
✅ 오늘의 문제 : BeautifulSoup 활용하기
6일차에 받아 왔던 HTML 코드에서 유의미한 데이터를 추출해 출력해 보세요!
저는 1일차에 선정했던 네이버 웹툰의 요일 별 인기 웹툰의 이름을 출력해 보려고 해요.😀
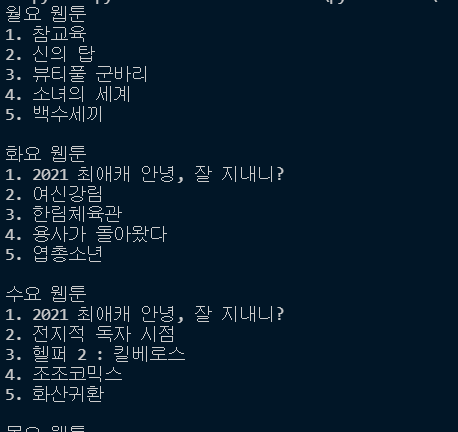
코드
import requests
import bs4
URL = 'https://cafe.naver.com/codeuniv'
raw = requests.get(URL)
html = bs4.BeautifulSoup(raw.text, 'html.parser')
target = html.find('div', {'id': 'cafe-menu'})
mo_list = target.find_all('a', {'class': 'gm-tcol-c'})
for i in range(len(mo_list)):
print(i+1, mo_list[i].text)
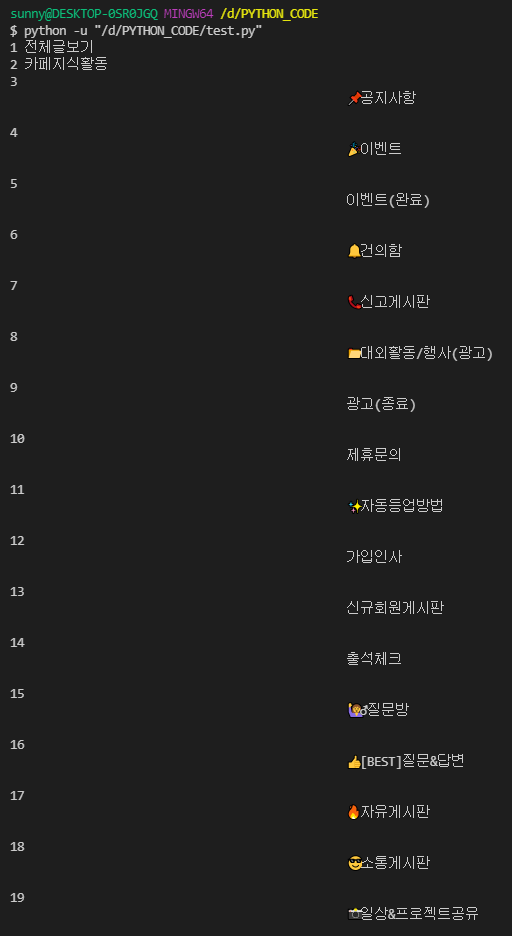
결과
728x90
'개발 > 코뮤니티' 카테고리의 다른 글
| [파이썬 크롤링] 8일차 : BeautifulSoup 활용하기 (0) | 2022.02.16 |
|---|---|
| [파이썬 크롤링] 6일차 : 파이썬으로 HTML 코드 가져오기 (0) | 2022.02.14 |
| [파이썬 크롤링] 5일차 : HTML 선택자 찾기 (0) | 2022.02.11 |